
生成式 AI 技術越趨成熟,企業對於大型語言模型的需求已經不再只停留在概念驗證階段,而是追求能夠穩定運行、安全合規且高效擴展的生產環境部署。Amazon Bedrock 作為 AWS 全託管的生成式 AI 服務平台,提供企業包括 Anthropic Claude 、Google Gemma 等多種先進基礎模型的存取能力。然而,在實際部署過程中,許多企業常常面臨權限配置複雜、配額管理不當、跨區域路由選擇困難等技術挑戰。
有鑑於此,博弘雲端近期成為 Anthropic 經銷合作夥伴,協助企業透過 Amazon Bedrock 一站式部署 Anthropic Claude 模型,帶您從存取權限的最佳實踐、跨區域架構的選擇策略,再到服務配額的優化管理與監控告警機制的建立,提供您一套完整的技術實踐指南。
Amazon Bedrock 存取 Anthropic Claude 模型權限的方式
Amazon Bedrock 是 AWS 推出的全託管 AI 服務平台,讓開發者能夠用「組建積木」的形式打造AI應用。此外,彈性選擇使用各大品牌AI模型的優勢,像是 Google Gemma、Moonshot AI Kimi、MiniMax 、Mistral AI 與 NVIDIA NEMOTRON 等,賦能企業根據應用情境選擇匹配的工具。
不過想要透過 Amazon Bedrock 訪問模型,得要靠API串接才行。舉例來說,倘若要透過 API 訪問 Amazon Bedrock 上的Anthropic Claude 模型,需要從主控台中取得對應的端點 (Endpoint)。在取得端點後,接續設定權限的驗證方法,是保護連接安全的關鍵。目前主要有兩種方式:
Access Key / Secret Key:傳統 IAM 身分驗證機制
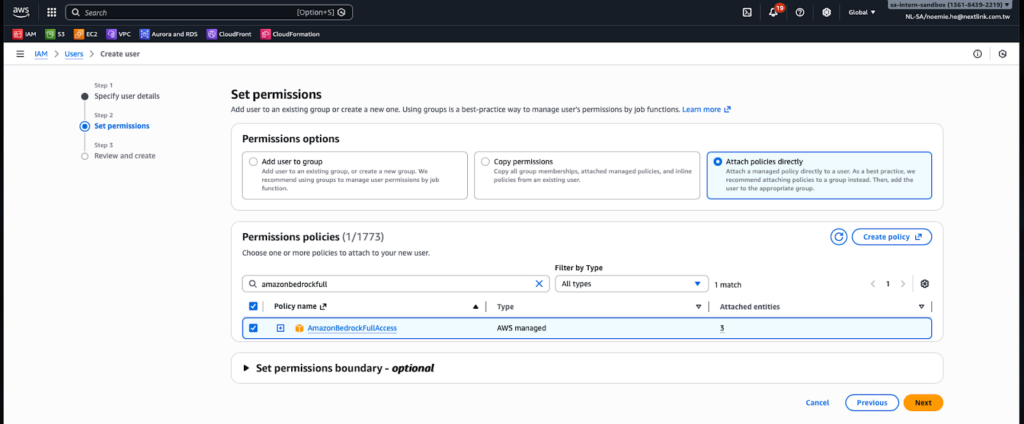
在 Amazon Bedrock 推出初期,開發者主要透過 AWS IAM 的 Access Key 與 Secret Key 來進行身分驗證。這種方式需要先創建 IAM User (使用者),為該使用者配置 Amazon Bedrock 的相關權限,然後在 Security Credentials 頁籤下建立 Access Key。
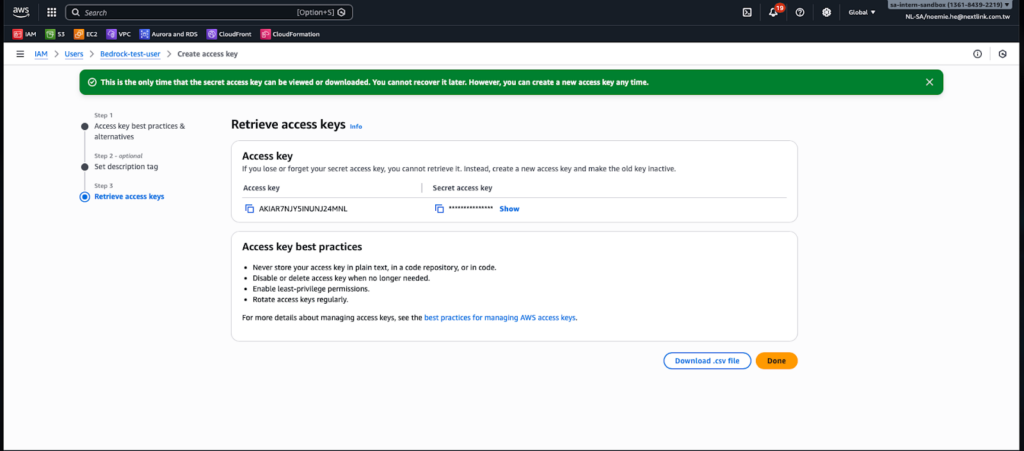
雖然傳統的 Access Key 與 Secret Key 機制功能完整,但在權限管理上存在潛在風險。如果 IAM 政策配置不當,持有這組憑證的使用者可能獲得超出 Amazon Bedrock 範圍的服務存取權限,間接造成資安隱患。此外,一旦建立完成 Access Key,只會在當下顯示一次 Secret Key,因此務必妥善保存並下載憑證,避免遺失後需要重新建立。
專為 Bedrock 設計的簡化開發 – API Key
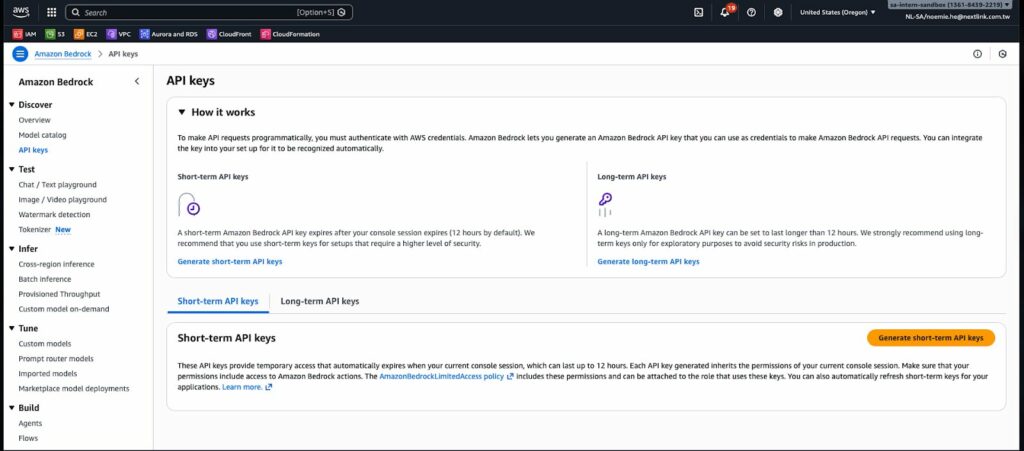
為了解決傳統的 Access Key 與 Secret Key 權限機制可能帶來的安全風險,AWS 在先前推出專為 Amazon Bedrock 設計的 API Key 功能。這項機制大幅簡化開發流程,同時提升安全性。
- API Key 的核心優勢:API Key 最大的特點在於其權限範圍被嚴格限縮在 Amazon Bedrock 服務內,即使 API Key 外洩,攻擊者也無法藉此存取其他 AWS 服務資源。在建立 API Key 時,開發者可以選擇「短期」或「長期」兩種類型。短期 API Key 會在 Console Session 對話過期後 12 小時自動失效,適合用於開發測試環境;而長期 API Key 則適合生產環境的長期穩定運行,但也得做好金鑰管理,避免設定成為公開狀態,導致曝光與外洩。
- 建立 API Key 的步驟:在 Amazon Bedrock 主控台的左側導航欄中選擇「API Keys」選項,系統會引導選擇金鑰類型。基於零信任安全原則,博弘雲端架構師建議優先採用短期 API Keys,並搭配自動化的金鑰輪替機制,確保即使在高頻使用場景下也能維持最佳的安全防護等級。
在 Amazon Bedrock 該選擇全球或跨區域的部署策略?
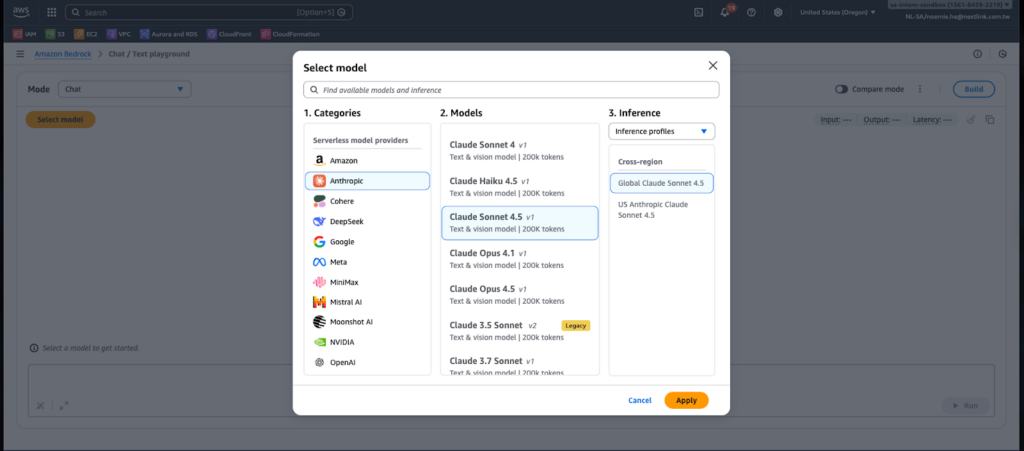
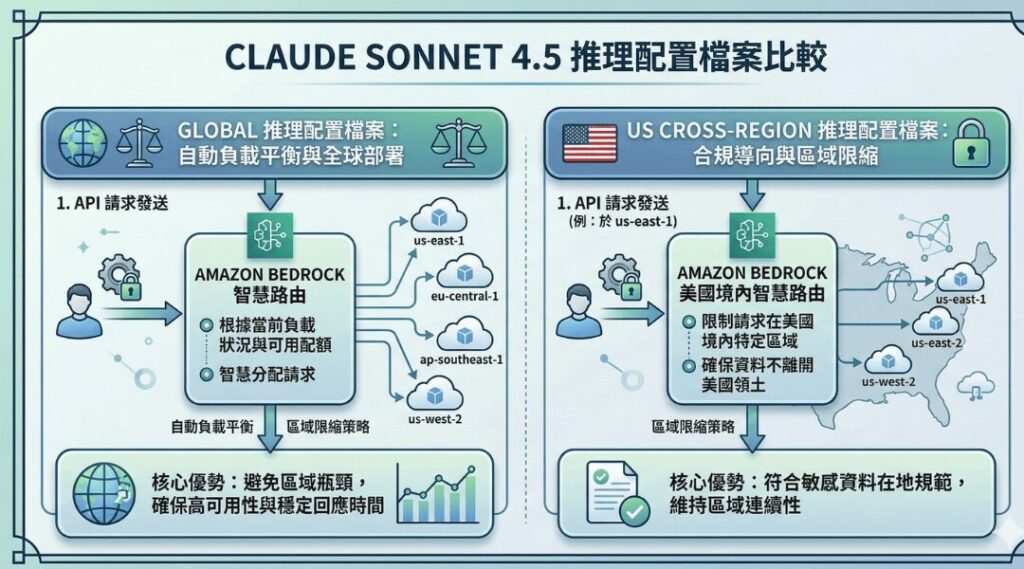
當開發人員在 Amazon Bedrock 中選擇 Anthropic Claude Sonnet 4.5 模型時,會發現系統提供了兩種不同的推理配置檔案 (Inference Profile),分別是「Global Claude Sonnet 4.5」與「 US Cross-Region Claude Sonnet 4.5」。這兩種推理配置的差別在哪裡?又能夠如何賦能企業既可以優化AI模型效能,也能夠兼顧符合合規?
Global 推理配置檔案:自動負載平衡的全球化部署
Global Claude Sonnet 4.5 採用智慧路由機制,當發送 API 請求時,Amazon Bedrock 會根據當前的負載狀況與可用配額,自動將請求分配到全球多個 AWS 區域中的模型副本,有效避免單一區域的配額耗盡或效能瓶頸,確保服務的高可用性與穩定回應時間。
US Cross-Region 推理配置檔案:合規導向的區域限縮策略
相對於 Global 配置的全球化路由,US Cross-Region Claude Sonnet 4.5 則將請求限制在美國境內的特定區域範圍內。以在 us-east-1 區域發起的請求為例,Amazon Bedrock 只會將請求路由到 us-east-1、us-east-2 或 us-west-2 這三個美國區域,確保資料處理過程不會離開美國本土。這樣的設計確保即使在單一區域發生配額限制或暫時性故障,請求仍能在同一地理範圍內完成處理,維持服務連續性也符合敏感資料的在地規範。
以 Claude Sonnet 4.5 為例:如何有效提高 Service Quotas
“Too many requests, please wait before trying again. You have sent too many requests. Wait before trying again.”
在實際使用 Anthropic Claude 模型的過程中,許多企業會遭遇「ThrottlingException」錯誤。當 AWS 傳回此錯誤時,代表應用程式已經觸及 Amazon Bedrock 的服務配額上限。配額服務的機制如何運作,以及該如何提升服務配額,才能讓生產環境能穩定運行?
Amazon Bedrock 為了維護服務穩定性與公平性,會對每個模型的推論請求設定多項配額 (quotas),包括:
Token per Minute:每分鐘 Token 處理上限
TPM 計算的是每分鐘內系統允許處理的 Token 總數,數字包含了輸入 (Input) 與輸出 (Output) 兩部分。然而,許多開發者容易忽略的是,即使 API 請求次數不多,只要單次請求的指令過長,像是包含大量文件內容的 RAG 應用,也很容易快速耗盡 TPM 配額。
Request per Minute (RPM):每分鐘 API 呼叫次數上限
RPM 限制的是每分鐘內可以發送的 API 請求總數,無論每個請求包含多少 Token,主要用於防止大量短時請求對系統造成的壓力。
Token per Day (TPD):每日累計 Token 使用總量
TPD 是一個更長週期的保護機制,用於控制每日的總體使用量。即使在某些時段的 TPM 與 RPM 都在限制範圍內,如果當天累計使用量已達上限,後續請求仍會遭拒絕。
為了讓企業的AI應用能夠穩定運行,開發人員可以在 AWS 主控台中的 Service Quotas 區塊,調整 Amazon Bedrock 的服務配額設定。此外,了解上下文長度對服務配額的影響,將能夠有策略性地配置運算資源。
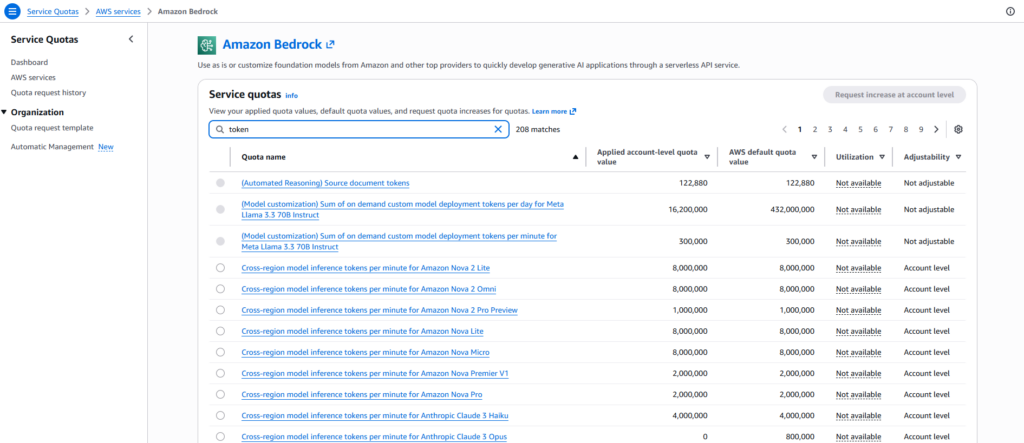
在 Amazon Bedrock 的 Service Quotas 清單中,您可以看到針對同一個模型有兩組不同的配額設定,差異在於「支援的上下文長度」:
標準版 (V1):適合一般對話與短文本處理
標準版的 Claude Sonnet 4.5 提供較高的 TPM 與 RPM 配額,非常適合處理一般性的對話、客服問答或中短篇內容生成任務。由於單次請求的上下文長度有限,系統能夠在同一時間內處理更多請求,因此配額相對寬鬆。
V1 1M Context Length:適合超長文本分析
當您需要讓 Claude 處理完整的法律合約、技術手冊或學術論文等超長文件時,就需要使用支援 1M (100 萬) Token 上下文的版本。然而,處理超長上下文對運算資源的需求極高,因此 AWS 會對這個版本施加更嚴格的配額限制,TPM 與 RPM 都會顯著降低。
如何申請提升服務配額
當預設配額無法滿足您的業務需求時,可以透過 AWS Service Quotas 主控台提交配額調整申請。申請過程通常需要 1-3 個工作日,因此建議在預期流量高峰前提早規劃。
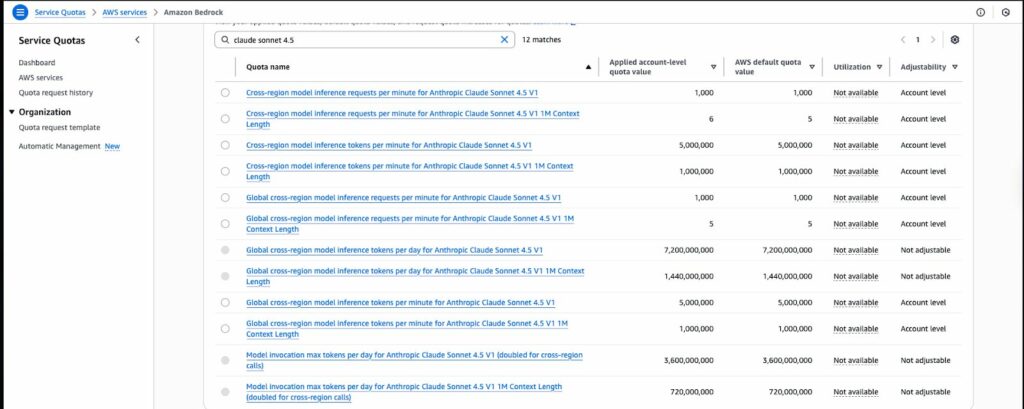
- 登入 AWS 管理主控台,前往 Service Quotas 服務
- 在搜尋欄中輸入「Amazon Bedrock」
- 找到對應的配額項目(例如「Claude Sonnet 4.5 – Tokens per minute」)
- 點選「Request quota increase」
- 填寫需要的配額數值與業務用途說明
- 提交申請並等待 AWS 團隊審核
透過 Amazon CloudWatch 建立完整的Amazon Bedrock監控與告警機制
前面我們提到Token 數量與 Request 次數配額將會大幅影響應用程式的效能,因此,建立完整的監控機制能夠達成即時告警,掌握 Amazon Bedrock 模型的運行狀況。透過 Amazon CloudWatch 的既有機制,掌握AI模型應用的效能與效率
監控 Token 使用量:整合 Input 與 Output
Amazon Bedrock 在 CloudWatch 中分別記錄了 InputTokenCount 與 OutputTokenCount 兩個指標,但如果要計算真實的 TPM 使用狀況,必須加總這兩個數值。建立 Token 監控儀表板的步驟:
- 進入 CloudWatch 主控台
- 選擇「Metrics」→「All metrics」
- 找到「AWS/Bedrock」命名空間
- 選擇「By ModelId」維度
- 勾選目標模型的 InputTokenCount 與 OutputTokenCount
- 點選「Graphed metrics」頁籤
- 選擇「Math expression」,輸入公式:m1 + m2(假設 m1 是 InputTokenCount, m2 是 OutputTokenCount)
- 將統計方式設定為「Sum」,時間區間設為 1 分鐘
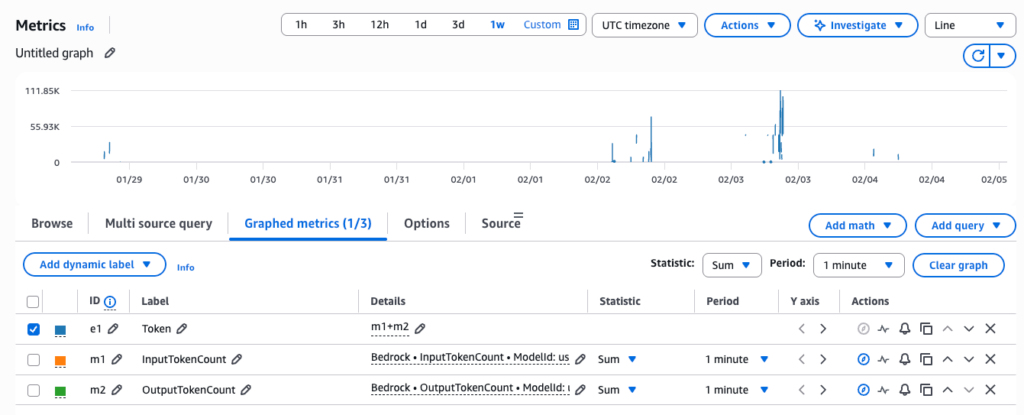
這樣就能在同一張圖表中看到完整的 TPM 使用趨勢。並與配額上限進行對比。
監控 Request 請求次數
Request per Minute (RPM) 的監控相對簡單,只需要追蹤 Invocations 指標即可。這個指標記錄了每分鐘內成功發送到模型的請求總數。建立 RPM 監控儀表板的步驟:
- 在 CloudWatch Metrics 中選擇「AWS/Bedrock」
- 選擇「By ModelId」維度
- 勾選目標模型的 Invocations
- 設定統計方式為「Sum」,時間區間為 1 分鐘
設定主動告警機制
僅有設定監控儀表板還不夠,還得建立自動化的告警規則,在使用量接近配額上限時主動通知運維團隊。建立 CloudWatch Alarm 的步驟:
- 在 CloudWatch 主控台中選擇「Alarms」→「Create alarm」
- 選擇前面建立的 Token 總和指標或 Invocations 指標
- 設定告警條件,例如:「當 TPM 超過配額的 80% 時觸發告警」
- 配置通知方式,選擇 SNS Topic(可串接 Email、Slack 或企業內部的事件管理系統)
- 設定告警名稱與描述,點選「Create alarm」
藉由了解存取權限、模型部署的地區差異,以及配額限制和監控告警,讓您在使用 Amazon Bedrock 部署 Anthropic Claude 模型時能夠達到商業與技術的最佳成效。隨著Anthropic Claude Sonnet 4.6 版本的模型現已在 Amazon Bedrock 推出,您更需要部署進階AI模型的顧問服務。立即聯繫博弘雲端,擁有 Anthropic 經銷合作夥伴資格以及 AWS AI Services 能力認證 (生成式 AI 級別),提供企業 AI 應用落地的解決方案,從零到一的應用情境,開拓AI服務的商業藍圖!