
生成式AI發展的速度,已經超乎我們的想像。2025年8月,OpenAI 公司旗下所推出的 GPT-5 模型,加入了客製化的「人物個性」,強調在分析、寫作與撰寫程式碼的功能特色上更加突出。人們日常對於AI仰賴度逐漸提升,也對迭代更新的AI模型也越加引頸期盼。近日 AWS 與 OpenAI 重磅宣布合作,在 Amazon Bedrock 與 Amazon SageMaker AI 服務中提供 OpenAI 的兩款開源權重(Open Weight)基礎模型: gpt-oss-120b 、gpt-oss-20b。
這兩款開源權重模型在AWS上的AI應用,對於想要在台灣快速落地生成式 AI 技術的企業來說是重要的機會。究竟開源權重模型在AWS上的表現、實戰應用與模型部署有哪些特色?博弘雲端將帶你深入了解這些模型的優勢、應用場景,以及如何立即啟動與部署 Open AI 的開源權重模型!
目錄
目錄
OpenAI 開源權重模型 on AWS!賦能企業靈活可控新選擇
OpenAI 的開源權重(Open Weight)模型,讓企業能直接存取並微調模型參數,突破封閉式 API 的限制,帶來更高的靈活性、可控性與安全性。在目前模型訓練的應用下,OpenAI 的開源權重模型可以帶來關鍵性的優勢:

OpenAI 開源權重模型的優勢
- 客製化訓練:針對企業內部資料進行專屬的模型優化
- 合規與治理:滿足金融、醫療等特定產業對資料治理與法規合規的要求
- 成本效益:有效降低長期授權費用與運算成本
因此,借重這些優勢,在 AWS 環境中部署OpenAI 的開源權重模型時,gpt-oss 系列展現出效能的高性價比。經過實測發現,與 Google Gemini 相比,效能提升 10 倍;與 DeepSeek-R1 相比,高出 18 倍;甚至比 OpenAI o4 還要高出 7 倍。這樣的實測結果代表企業可以在相同預算下,獲得更快速的回應、更高的吞吐量,並有效降低 AI 專案的長期營運支出。

OpenAI on AWS 具備高性價比的運算力
除了效能優勢之外,這兩款模型還支援長達 128K Token 的上下文處理能力,足以應對需要長時間記憶與理解的複雜任務。無論是上萬字的技術文件、完整的客服對話記錄,或是篇幅龐大的研究報告與白皮書,都能一次性輸入並保持前後語境一致,避免資訊遺漏或斷裂。
OpenAI on AWS 多元業務應用的AI最佳助手
我們在先前的文章曾經提到,企業導入AI技術時,前置作業的盤點必須落實「商業目標與資源配置的一致性」,才能確保AI應用發揮最大的功效。而這次 OpenAI 的兩個開源權重模型(gpt-oss-120b 、gpt-oss-20b),在AWS服務應用上將能夠針對不同的應用情境給予解決方案,整合應用場景與實際AI落地,達到安全可控與符合合規性的AI應用。

OpenAI on AWS 的實戰應用
| 應用場景 | 實際做法 | 預期效益 |
|---|---|---|
| 智慧客服中心 | 在 Amazon Bedrock 上建立 AI Agent,串接知識庫與客服系統。 | 自動回應 80% 常見問題,降低人力成本 |
| 合約與法規分析 | 以Open AI 權重模型中 128K Token 的特色,處理長篇法規與合約,生成摘要與風險提示。 | 審核速度提升 3 倍 |
| 科學與財務分析 | 在 Amazon SageMaker 中微調模型,處理統計與數據分析相關任務。 | 分析精準度與效率同步提升 |
| 軟體開發輔助 | 結合 OpenAI API 的 Code Interpreter,自動生成與除錯程式碼。 | 開發時程縮短 30%-50% |
| 跨語言文件處理 | 即時翻譯與摘要技術文件,相較其他模型具備更高的精準度。 | 縮短跨國溝通時間 |
OpenAI 模型 on AWS 從 0 到落地的導入步驟
如何將 OpenAI 新的開源權重模型導入至AWS雲端環境中?透過 Amazon Bedrock 與 Amazon SageMaker 的設定,從0到1的 OpenAI on AWS 導入全面步驟,協助企業運用開源權重模型達到更精確的推論:
步驟 1:確認前置條件與環境準備
在進入部署之前,企業在AWS雲端帳戶中必須確保已具備以下條件:
- AWS 帳號與資源控管:確認 IAM 權限允許存取 SageMaker 與對應資源。
- SageMaker Studio 存取權限:建議透過 SageMaker Studio 進行部署,以簡化操作與測試流程。
- 適用的運算資源:根據模型大小選擇合適的 GPU Instance,例如 gpt-oss-120b 預設建議使用 p5.48xlarge,並檢查 Service Quotas 是否足夠,必要時先申請額度提升。
- 部署區域:目前支援 US East (N. Virginia、Ohio) 與 Asia Pacific (Mumbai、Tokyo),建議選擇距離業務近的區域以降低延遲。
步驟 2:透過 Amazon SageMaker JumpStart 查找模型
- 進入 SageMaker Studio,在左側選單點選 JumpStart。 在搜尋框輸入 gpt-oss-120b 或 gpt-oss-20b,即可找到對應的模型卡(Model Card)。
- 點選模型卡即可檢視詳細資訊,包括授權條款、訓練資料來源、使用建議與最佳化提示。
- 在進行部署前,請先評估是否需要調整模型的推論邏輯或與外部工具(如 Strands Agents)整合,以支援企業的 Agent Workflow。
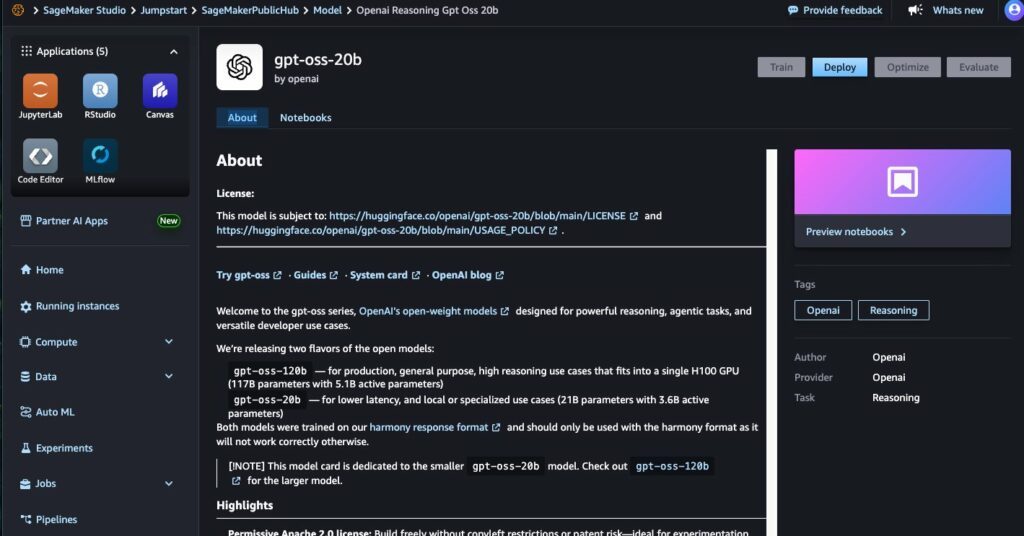
步驟 3:設定部署參數
- 在模型卡頁面點擊 Deploy。
- Endpoint 名稱:輸入 50 個字元以內的英數名稱,方便後續辨識。
- Instance 類型:選擇適合的 GPU Instance,以確保推論速度與效能。
- Instance 數量:依照業務需求與流量預估設定,預設為 1,並透過 Auto Scaling Policy 依照業務需求調整。 確認設定後,點選 Deploy 進行部署。
步驟 4:等待並驗證部署結果
- Amazon SageMaker 會自動建立並啟用端點(Endpoint),當狀態顯示 InService 即表示模型可供使用。
- 可使用 SageMaker Runtime Client 或 Python SDK 呼叫該端點,進行即時推論測試。
- 建議在此階段透過 SageMaker Debugger 或 Container Logs 監控資源使用情況與模型效能,確保部署穩定性。
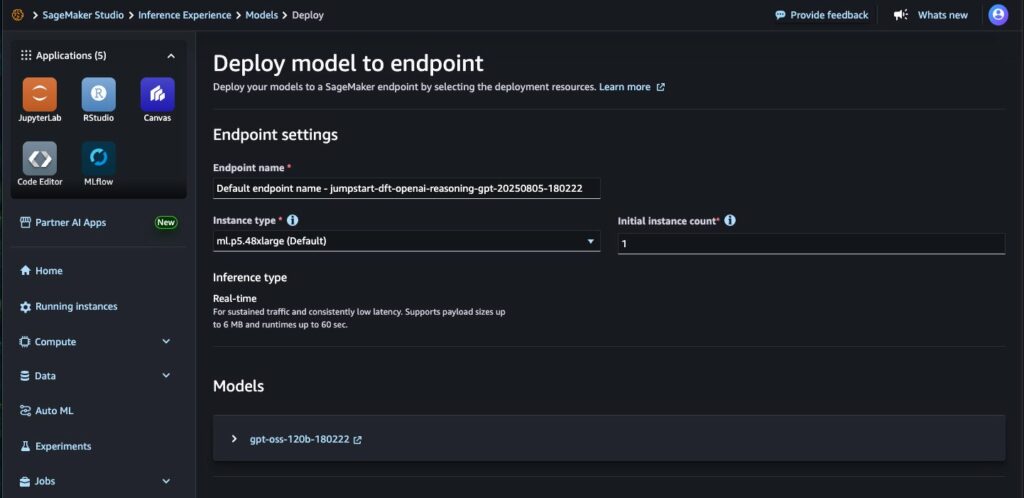
步驟 5:與應用系統整合
- 透過 OpenAI SDK 或自訂 API 呼叫 SageMaker 端點,將 GPT OSS 模型融入既有系統(如客服平台、財務分析系統、文件摘要工具等)。
- 可搭配 SageMaker Pipelines 實現 MLOps 流程,自動化模型更新與版本管理。
- 若業務涉及高安全性資料,可透過 VPC 控管 確保推論資料流量不經公開網路。
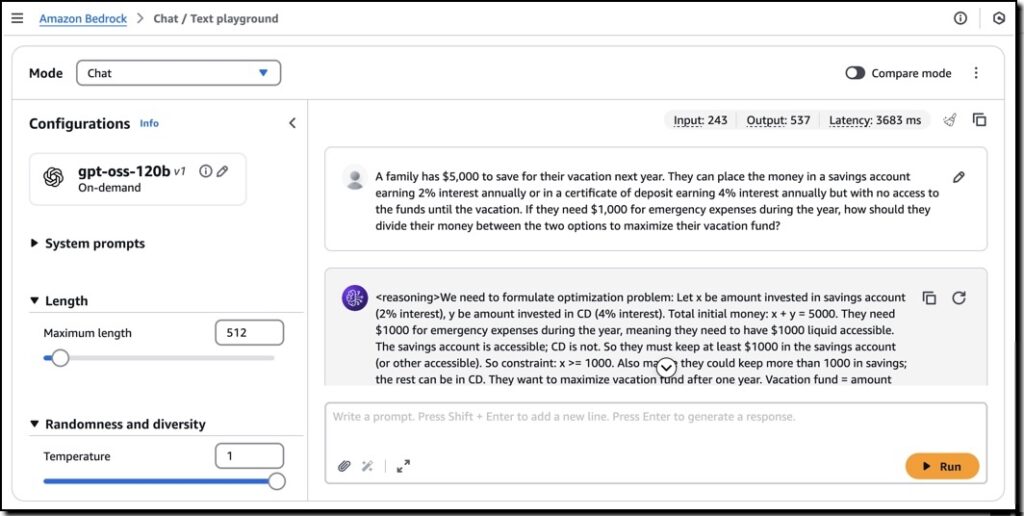
步驟 6:持續優化與擴展
- 依據實際使用情況調整推論參數(如 Reasoning Level 設為 Low/Medium/High)以平衡效能與成本。
- 若需要更高效能或多地部署,可透過多區域(Multi-Region)策略分散流量。 定期回顧監控指標(延遲、吞吐量、成本),並在必要時更新模型或擴充資源。
看完這六個步驟教學,部署 OpenAI 最新開源權重模型在AWS AI服務上,您是否也好奇如何實踐企業導入AI的應用與成效?立即與博弘雲端專業的架構師團隊聯繫,評估企業現階段的需求與資源,從POC測試開始,優化業務營運發展。乘著AI浪潮,用前瞻科技掌握關鍵局勢!




